Автоматизация рутины в OS X. Урок 6. Простейший парсинг веб-страниц

В каждом из нас на уровне инстинктов есть сильнейшая потребность исследовать окружающий мир. Она помогает выживанию и способствует развитию цивилизации. Но в последние лет сто он наносит значительный вред представителям человеческого рода, не давая отрываться от экрана телевизора и заставляя бесконечно кликать на ссылках в новостной ленте. В решении последней проблемы поможет Java Script Automation.
Что мы будем делать?
«Вытащим» заголовки первого, второго и третьего уровня со всех страниц открытых в браузере и вставим их текстовый файл. Это позволит единым взором посмотреть о чем сегодня пишут новостные сайты, лишив себя возможности немедленно перейти по ссылке. С одной стороны, чтение такого файла не даст задохнуться в информационном вакууме и пропустить реально важные события («Закрыли метро», «Обменники не принимают доллары»). А с другой в несколько раз сократит время на прочтение новостных заголовков и убережет от соблазна залипнуть на час переходя от новости к новости.
Куда писать Java Script код?
- Открыть программу «Редактор скриптов» (Программы -> Утилиты).
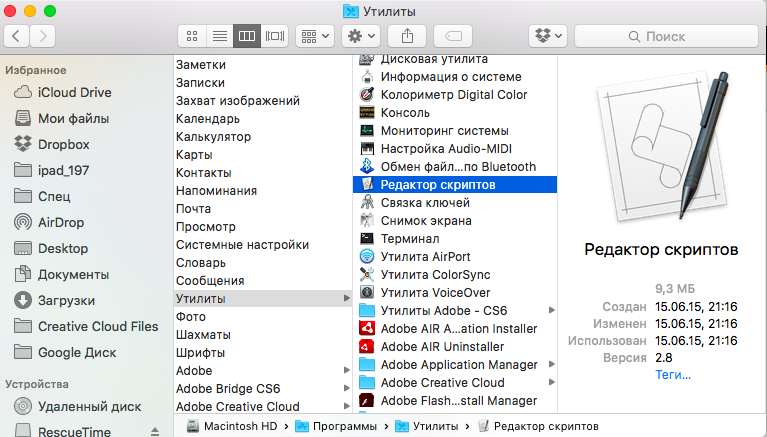
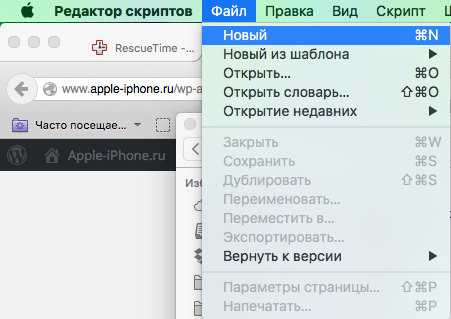
- В верхнем меню выбрать Файл -> Новый.
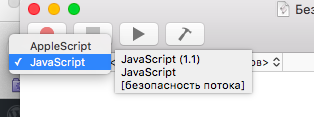
- На переключателе языков выбрать JavaScript.
Как получить исходный код веб-страницы?
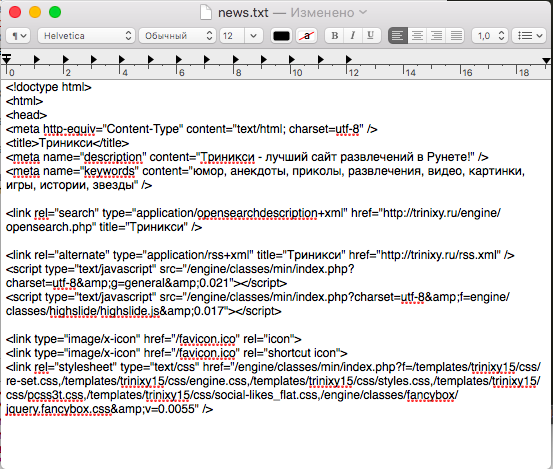 Заголовки мы будем извлекать из исходного кода страницы, (который можно посмотреть нажав сочетания клавиш Command+Option+U):
Заголовки мы будем извлекать из исходного кода страницы, (который можно посмотреть нажав сочетания клавиш Command+Option+U):
// Кладем в переменную браузер Safari (аналогичный скрипт работает для Firefox и Google Chrome)
var Safari = Application("Safari");
// Кладем в переменную текстовый редактор
var textEdit = Application("TextEdit");
// Создаем в текстовом редакторе новый файл
var newDoc = textEdit.Document().make();
//Присваиваем ему имя
newDoc.name = "news.txt";
//Создаем пустую переменную для исходного кода страницы
var content = "";
//Кладем в переменную окно браузера к которому будем обращаться
var window = Safari.windows[0];
//Получаем исходный код первой вкладки окна с помощью метода source().
content = window.tabs[0].source();
//Записываем исходный код в текстовый файл
textEdit.documents["news.txt"].text = content;Если бы html-теги нам были не нужны, то мы бы использовали метод text().
Как извлечь заголовки из исходного кода страницы?
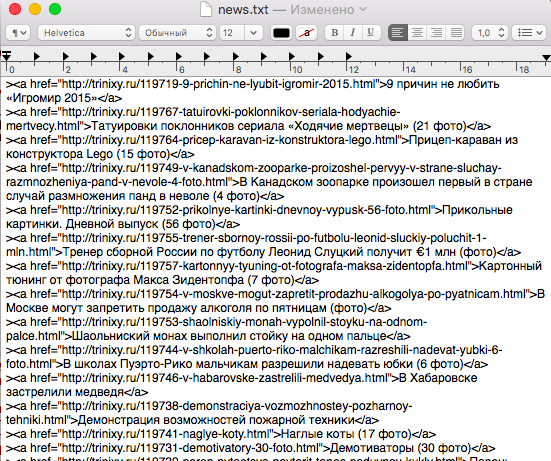 Теперь нам нужно извлечь из огромной простыни сложно читаемых символов самую важную информацию, которая хранится в заголовках второго уровня, обозначаемых тегом «<h2>». Для этого мы будем использовать цикл for и метод split(), который преобразует строку в массив в соответствии с заданным разделителем:
Теперь нам нужно извлечь из огромной простыни сложно читаемых символов самую важную информацию, которая хранится в заголовках второго уровня, обозначаемых тегом «<h2>». Для этого мы будем использовать цикл for и метод split(), который преобразует строку в массив в соответствии с заданным разделителем:
// Кладем в переменные браузер и текстовый редактор
var Safari = Application("Safari");
var textEdit = Application("TextEdit");
// Создаем новый файл и присваиваем ему имя
var newDoc = textEdit.Document().make();
newDoc.name = "news.txt";
// Создаем переменные для исходника страницы и строк с заголовками
var content = "";
var headersText = "";
//Кладем в переменную окно браузера к которому будем обращаться
var window = Safari.windows[0];
//Кладем в переменную исходник веб-страницы
content = content + window.tabs[0].source();
//Создаем два служебных пустых массива, которые будем использовать для парсинга контента с помощью метода split
var contentArray = new Array();
var contentArray2 = new Array();
//Кладем в первый массив отрезки исходника от <h2> до <h2
var contentArray = content.split("<h2");
for (j = 1; j < contentArray.length; j=j+2) {
//Обрезаем каждый отрезок до </h2 (закрытие тега заголовка)
contentArray2 = contentArray[j].split("</h2");
//Прикрепляем заголовок к списку
headersText = headersText + contentArray2[0] + "\n";
}
//Записываем все заголовки в текстовый файл
textEdit.documents["news.txt"].text = headersText;В итоге мы имеем примерно следующие текстовые строки, каждая из которых содержит новостной заголовок и ссылку на новость:
><a href="http://trinixy.ru/119719-9-prichin-ne-lyubit-igromir-2015.html">9 причин не любить «Игромир 2015»</a> ><a href="http://trinixy.ru/119767-tatuirovki-poklonnikov-seriala-hodyachie-mertvecy.html">Татуировки поклонников сериала «Ходячие мертвецы» (21 фото)</a> ><a href="http://trinixy.ru/119764-pricep-karavan-iz-konstruktora-lego.html">Прицеп-караван из конструктора Lego (15 фото)</a> ><a href="http://trinixy.ru/119749-v-kanadskom-zooparke-proizoshel-pervyy-v-strane-sluchay-razmnozheniya-pand-v-nevole-4-foto.html">В Канадском зоопарке произошел первый в стране случай размножения панд в неволе (4 фото)</a>
Как проделать вышеописанное сразу с несколькими вкладками?
 Теперь немного модифицируем наш код, чтобы он собирал заголовки сразу с нескольких новостных сайтов:
Теперь немного модифицируем наш код, чтобы он собирал заголовки сразу с нескольких новостных сайтов:
// Кладем в переменные браузер и текстовый редактор
var Safari = Application("Safari");
var textEdit = Application("TextEdit");
// Создаем новый файл и присваиваем ему имя
var newDoc = textEdit.Document().make();
newDoc.name = "news.txt";
// Создаем переменные для исходника страницы и строк с заголовками
var content = "";
var headersText = "";
//Кладем в переменную окно браузера к которому будем обращаться
var window = Safari.windows[0];
for (i=0;i<=1;i++)
{
//Кладем в переменную исходник веб-страницы во вкладке соответствующей итерации цикла
content = content + window.tabs[i].source();
//Создаем два служебных пустых массива, которые будем использовать для парсинга контента с помощью метода split
var contentArray = new Array();
var contentArray2 = new Array();
//Кладем в первый массив отрезки исходника от <h2> до <h2
var contentArray = content.split("<h2");
for (j = 1; j < contentArray.length; j=j+2) {
//Обрезаем каждый отрезок до </h2 (закрытие тега заголовка)
contentArray2 = contentArray[j].split("</h2");
//Прикрепляем заголовок к списку
headersText = headersText + contentArray2[0] + "\n";
}
}
//Записываем все заголовки в текстовый файл
textEdit.documents["news.txt"].text = headersText;
Предыдущие публикации из цикла «Автоматизация рутины в OS X» вы можете найти по следующим ссылкам:
- Автоматизация рутины в OS X. Урок 1. Пакетная обработка изображений
- Автоматизация рутины в OS X. Урок 2. Генерация слайдов для презентаций
- Автоматизация рутины в OS X. Урок 3. Рассылаем спам
- Автоматизация рутины в OS X. Урок 4. Простейший парсинг почтового ящика
- Автоматизация рутины в OS X. Урок 5. Пакетная конвертация текстовых файлов
Знай и используй:
- Хранилище iCloud — как очистить
- Как загрузить фильм в iTunes
- Как перекинуть фото с айфона на компьютер
✅ Подписывайтесь на нас в Telegram, Max, ВКонтакте, и Яндекс.Дзен.